核心发现
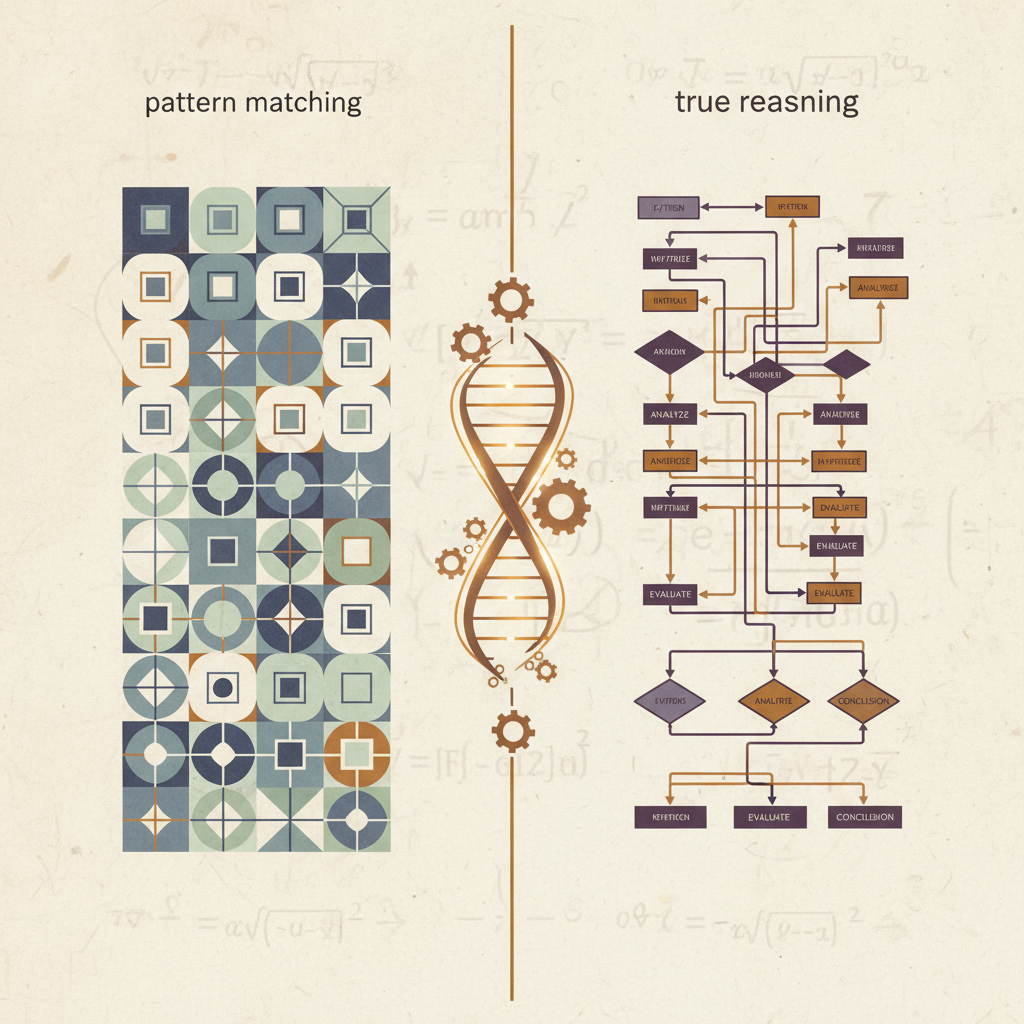
思考幻觉
LLM展现出的推理能力可能并非真正的逻辑演绎,而是一种基于海量数据训练出的高级"模式匹配"
• Apple研究:10%性能下降
• 变量敏感性测试
• 模式匹配vs真正推理
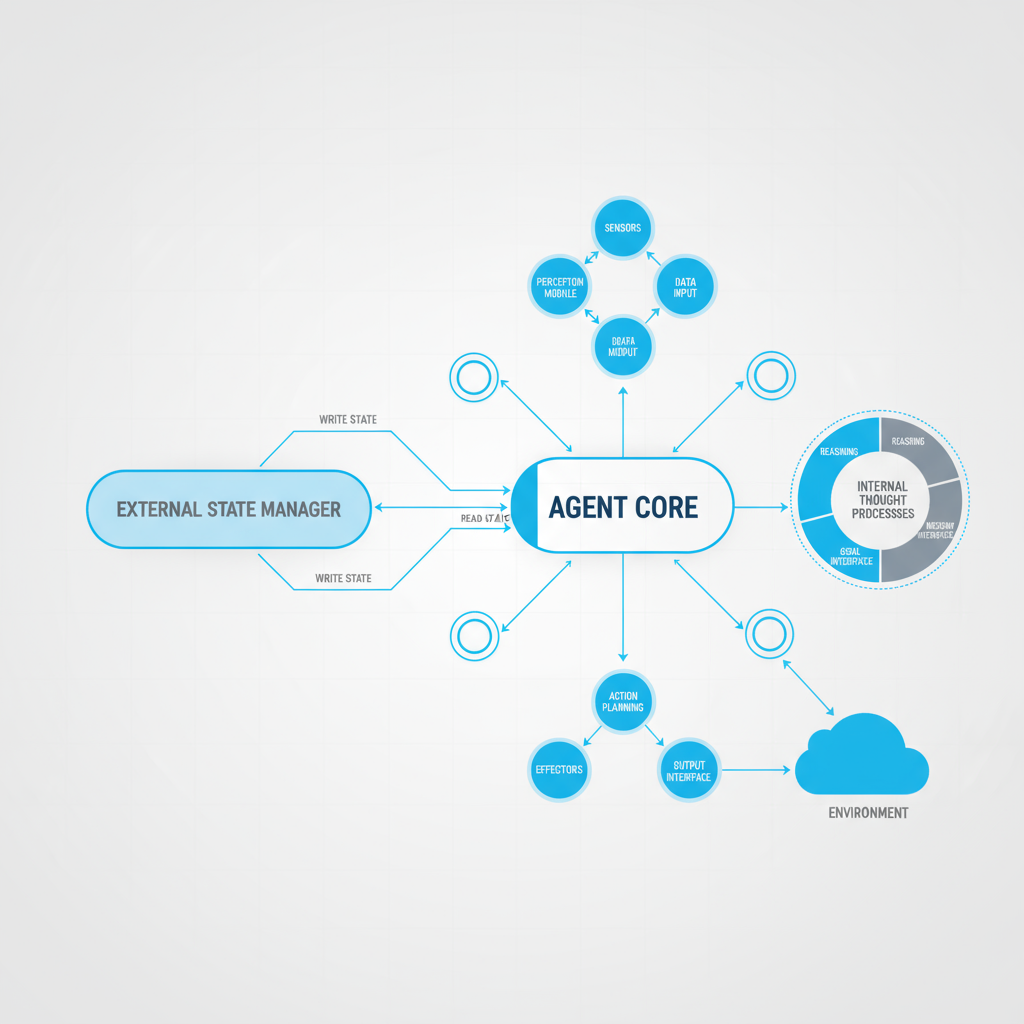
智能体框架
通过将"状态管理"外部化,剥离记忆负担,测试LLM最纯粹的动态规划和推理能力
• 状态外部化设计
• 记忆负担剥离
• 纯粹推理能力测试

性能崩坏
LLM在处理汉诺塔问题时,当盘子数量达到临界点,成功率从接近完美骤降至几乎为零
• 5-6个盘子临界点
• 成功率骤降现象
• 三个性能区域

确定性循环
模型在遇到困难时,会陷入无法逃脱的固定无效动作循环,反复"明知故犯"
• 固定错误模式
• 无法自我纠正
• 认知陷阱机制